If you’re still building classifiers based on annotated isolated images instead of annotated videos, you’re losing valuable information, getting lower quality annotations, spending more money, and walking away from much more training data. Read on to learn why and how you can transition to scalable, fast, and cost-effective video annotation.
This story is about a young boy with a video camera. That boy is me, a 13-year old celebrating his Bar Mitzvah, who just received his first video camera as a present from his uncle. Already back then, I realized the huge advantage of video over still images. All of a sudden, all my memories could be brought to life. Compared to pictures from my pocket film camera, video was instantaneous, lively, and interactive.
But we digress… You are a machine learning expert, why would you care about the sweet memories of a little kid? Your interest lies squarely with the sophisticated, fast, unique image classifier you’ve trained. It detects unicorns in YouTube videos, and next step is profit $$$. With enough GPUs, you can classify all new uploads to YouTube in real time, even on 4K@60FPS. You’ve trumped yolo. You’re a prodigy. This classifier goes to 11.
Training was easy; all you had to do was scrape all the YouTube unicorns videos, extract a few frames from each, manually annotate each frame with a bounding box around each unicorn (that took a week, and what a boring week!), and feed to your training infrastructure (that also took a week). The trained classifier is simple to use: you break each video into gazillion images and feed each image to your trained neural net. Simple!
Does this sound familiar?
What if you could create more meaningful annotations on video, and do it in a way that is cheaper & faster?
What if you could have a 10x more training data, and more accurate data to boot?
Your videos actually contain much more. Capturing movement is only possible in video, which stores temporal features in addition to the image data. Why not take advantage of the fact your training data comes from a video source?
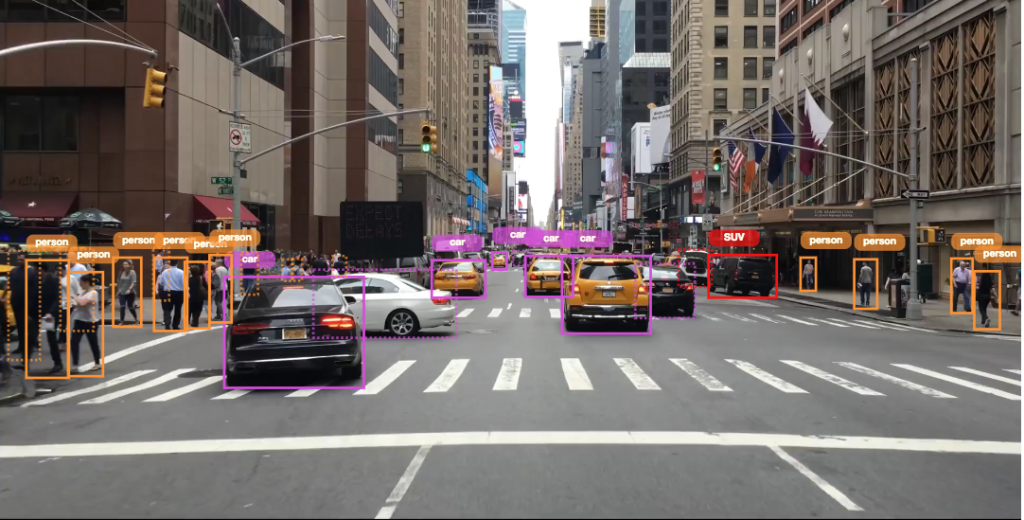
Let’s say you’re training a classifier to detect what’s in front of an autonomous car. The training data likely comes from a video camera, and yet you treat the video as a sequence of isolated still images, sampled from the video at a low frame rate. You use still images for preparing ground truth data, for training, and for classifying.
Even if you’re building a still-image classifier – annotating on video will make it an order of magnitude better.
Your image classifier may achieve great results on most frames. However, under difficult light conditions, or when the target object is partially occluded, your classifier’s accuracy may drop. Taking advantage of information from previous frames could be the difference between hitting a pedestrian crossing the road to identifying her and accurately predicting her future path on the road.
” …the self-driving system software classified the pedestrian as an unknown object, as a vehicle, and then as a bicycle with varying expectations of future travel path.” NTSB
But I don’t want to annotate videos! Images are simpler to deal with.
There are various reasons why treating video as a sequence of still images was the common choice:
- It’s easier to build classifiers that handle images, not video. Today, Recurrent Neural Networks (RNNs) make it simpler and more meaningful to process video.
- Annotating an image is by far simpler than annotating a video. Video is a complex data structure, and everything about it is harder. To annotate on video, you have to handle incompatible codecs and video players, synchronize annotations between frames, track multiple annotated objects with varying states along multiple frames, and design UX to enable complex operations. To top it all, in a 10 second video you likely need to annotate 300 images.
Both of these reasons do not hold anymore. Today, services like Clay Sciences (shameless plug – that’s us) can annotate your videos on demand.
And once you have all this training data, using Recurrent Neural Networks (RNNs), you can process video frames as a sequence, as opposed to disparate images.
Why annotating directly on video is superior to annotating images
At Clay Sciences, we developed annotation tools that work directly on videos. Here are few of the benefits we unlocked by doing so:
- Tracking with consistent IDs – annotating videos makes tracking of the detected objects for the duration of the video simpler – including when objects move in and out of frame, and when their order shuffles.
- Annotating temporal features – Is that car signaling for a turn? Is that person sitting down or standing up? These questions can be easily answered in videos.
- Better quality – real-life objects tend to move in continuous fashion, and annotating on video naturally follows the object movement using interpolation. However, when annotating on disparate images, annotations can move arbitrarily between consequent frames.
- Cost and error reduction – annotations on video can be interpolated between key frames, which significantly reduces the annotation effort. For slow moving objects, instead of laboriously annotating each frame (and introducing errors while doing so), the manual updates between keyframes on video can be almost immediate, so long videos can be annotated much faster, and with fewer errors.
- More training data = better training – it is widely accepted that more training data leads to higher accuracy classifiers. Annotating on video can produce 15-30x more training data than annotating images. Even if you’re building a still-image classifier – annotating on video will make it an order of magnitude better.
- Automated tracking – annotating on video allows us to embed tracking algorithms in the annotation tools. Once manual annotation starts, automated tracking takes over and turns manual annotation into a matter of verifying and correcting the predictions provided by automated trackers. This leads to faster and better annotations.
If this sounds interesting, feel free to contact us (info@claysciences.com). Learn more on our website.